Follow the procedure in sequence as given below .
step 1 : Installation of Java 1.7/1.6 .
Check the existence of java


Go to the JVM folder and check the existence of multiple
JAVA installation.


Install the JAVA

 Enter
“Y” when the question is asked.
Enter
“Y” when the question is asked.
step 3: Download Hadoop from Apache.
$ wget http://apache.mirrors.hoobly.com/hadoop/common/stable/hadoop-2.2.0.tar.gz
$ cd /home/hadoop
$ tar xzf hadoop-2.2.0.tar.gz
$ mv hadoop-2.2.0 /usr/local/hadoop
step 4: Single Node Cluster – Setup
i. Goto /usr/local/hadoop/etc/Hadoop/
ii. Edit hadoop_env.sh and add JAVA_HOME set path of Sun

Goto /home/hadoop/Downloads/hadoop-2.2.0/bin

Do the setup below in the directory
/home/hadoop/Downloads/hadoop-2.2.0/etc/hadoop
Format Name-node for first time use
===========================
/home/hadoop/Downloads/hadoop-2.2.0/sbin /hadoop namenode –format
Start hadoop deamons
=============================\
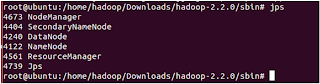
/home/hadoop/Downloads/hadoop-2.2.0/sbin /start-dfs.sh
/home/hadoop/Downloads/hadoop-2.2.0/sbin /start-yarn.sh
step 1 : Installation of Java 1.7/1.6 .
Check the existence of java

If it does exist, remove all the installation and have the
JVM folder clean( Please note that there should be no files or folder in the JVM directory )

Uninstall the JAVA settings
step 2: Installation of SSH
Steps to be followed :
i. sudo apt-get install ssh
ii. su - root
iii. ssh-keygen -t rsa -P
""
iv. cat $HOME/.ssh/id_rsa.pub >>
$HOME/.ssh/authorized_keys
v. ssh localhost
The "ssh localhost" should result in below :
step 3: Download Hadoop from Apache.
$ wget http://apache.mirrors.hoobly.com/hadoop/common/stable/hadoop-2.2.0.tar.gz
$ cd /home/hadoop
$ tar xzf hadoop-2.2.0.tar.gz
$ mv hadoop-2.2.0 /usr/local/hadoop
step 4: Single Node Cluster – Setup
i. Goto /usr/local/hadoop/etc/Hadoop/
ii. Edit hadoop_env.sh and add JAVA_HOME set path of Sun
iii. To find JDK folder , type “whereis jvm”

Goto /home/hadoop/Downloads/hadoop-2.2.0/bin
The
Result should look like this

Do the setup below in the directory
/home/hadoop/Downloads/hadoop-2.2.0/etc/hadoop
core-sites.xml
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>
hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
</configuration>
map-reduce.xml
<configuration>
<property>
<name>mapred.job.tracker</name>
<value>localhost:9001</value>
</property>
</configuration>
Format Name-node for first time use
===========================
/home/hadoop/Downloads/hadoop-2.2.0/sbin /hadoop namenode –format
Start hadoop deamons
=============================\
/home/hadoop/Downloads/hadoop-2.2.0/sbin /start-dfs.sh
/home/hadoop/Downloads/hadoop-2.2.0/sbin /start-yarn.sh

Web interface available
=================
NameNode - http://localhost:50070/
JobTracker - http://localhost:50030/
Stop hadoop deamons
=================
/home/hadoop/Downloads/hadoop-2.2.0/sbin /stop-dfs.sh
/home/hadoop/Downloads/hadoop-2.2.0/sbin /stop-yarn.sh
No comments:
Post a Comment