This blog is meant for individuals who are non-Java professionals and for whom creating a .Jar file and executing them as Hadoop program is a big challenge .
Assumptions :
1. Eclipse is already installed on the machine .
2. Hadoop already installed or a VM is already available .
3. WinSCP already installed .
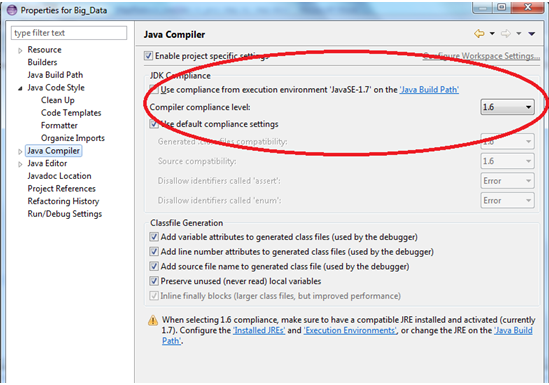
Step 0: Most importantly , please note that the version of Java installed on the LINUX/UBUNTU server
should be same as the ECLIPSE version where you are creating the .JAR.


Step 1 : Right Click on the folder and click "Export"

Step 2 : click on JAR file as shown below .

Step 3: click on the check box as shown . Give a Jar file name and click "Finish"




Assumptions :
1. Eclipse is already installed on the machine .
2. Hadoop already installed or a VM is already available .
3. WinSCP already installed .
Step 0: Most importantly , please note that the version of Java installed on the LINUX/UBUNTU server
should be same as the ECLIPSE version where you are creating the .JAR.

Execute the below steps one
by One

Step 2 : click on JAR file as shown below .

Step 3: click on the check box as shown . Give a Jar file name and click "Finish"

Step 4: COPY
AND PASTE THE SAME IN THE LINUX SERVER
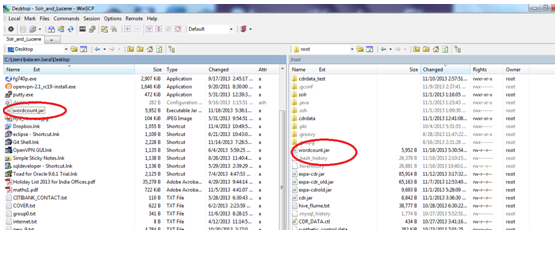
Step 5: Execute
the wordcount.jar using the below steps
hadoop jar wordcount.jar
inverika.training.examples.WordCount /user/root/data/input /user/root/data/output7
Please note that :
wordcount.Jat = Name of the jar file .
inverika.training.examples.WordCount = Package Name(dot) Class Name

Step 6 : Add all the .Jar that are needed to make your program error free

No comments:
Post a Comment